
What is Kernel Memory?
Kernel Memory is a multi-modal AI service designed for efficient indexing of datasets through custom continuous data hybrid pipelines. It supports Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a web service, Docker container, plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications.
Key Features of Kernel Memory
- Retrieval Augmented Generation (RAG): Enhances the ability to retrieve relevant information from indexed data and generate responses based on that information.
- Security Filters: Allows filtering memory by users and groups, ensuring controlled and secure data access.
- Long Running Ingestion: Supports long-running ingestion processes for large documents, complete with retry logic and durable queues for reliable data processing.
How Kernel Memory Works
Kernel Memory utilizes advanced embeddings and Large Language Models (LLMs) to enable natural language querying. It extracts text from various document formats, partitions the text into smaller chunks, and generates embeddings using an LLM. These embeddings are then stored in a vector index, such as Azure AI Search, allowing for efficient search and retrieval.
Data Ingestion Pipeline
- Extract Text: Recognize the file format and extract information.
- Partition Text: Divide the text into small chunks for optimized search.
- Generate Embeddings: Use an LLM to create embeddings from the text.
- Store Embeddings: Save the embeddings in a vector database for future retrieval.
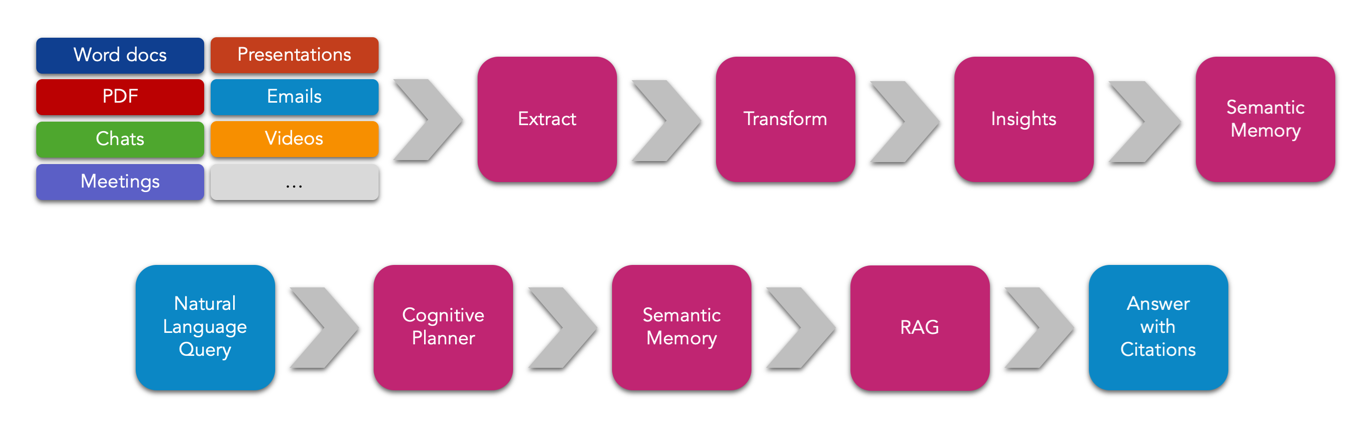
Synchronous Memory API (Serverless Mode)
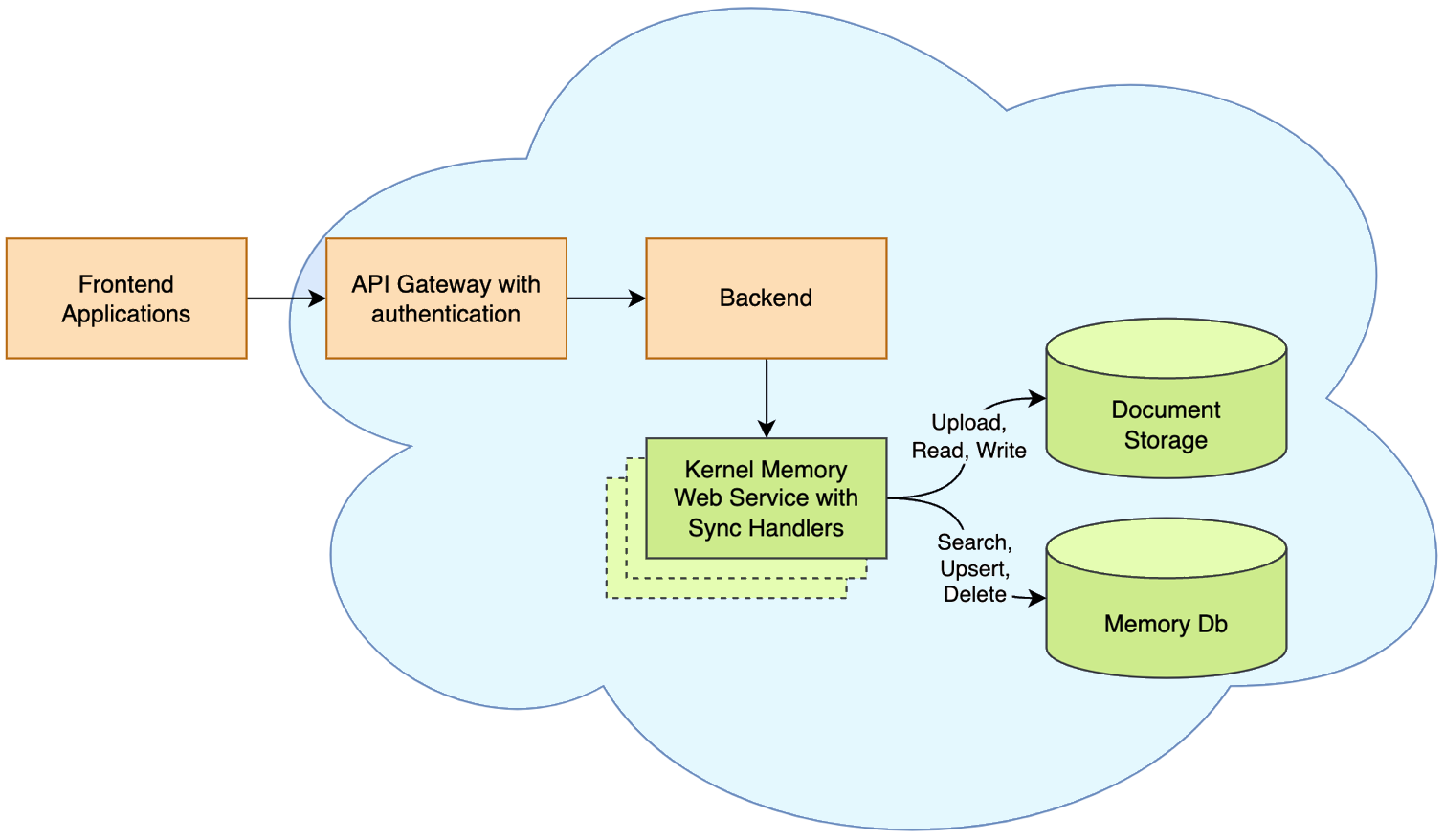
Kernel Memory performs optimally when running as an asynchronous web service, allowing for the ingestion of thousands of documents without blocking the application. However, it can also operate in a serverless mode by embedding the MemoryServerless class instance in .NET backend, console, or desktop applications in synchronous mode. This approach is effective in ASP.NET Web APIs and Azure Functions, where each request is processed immediately, though clients must handle transient errors.
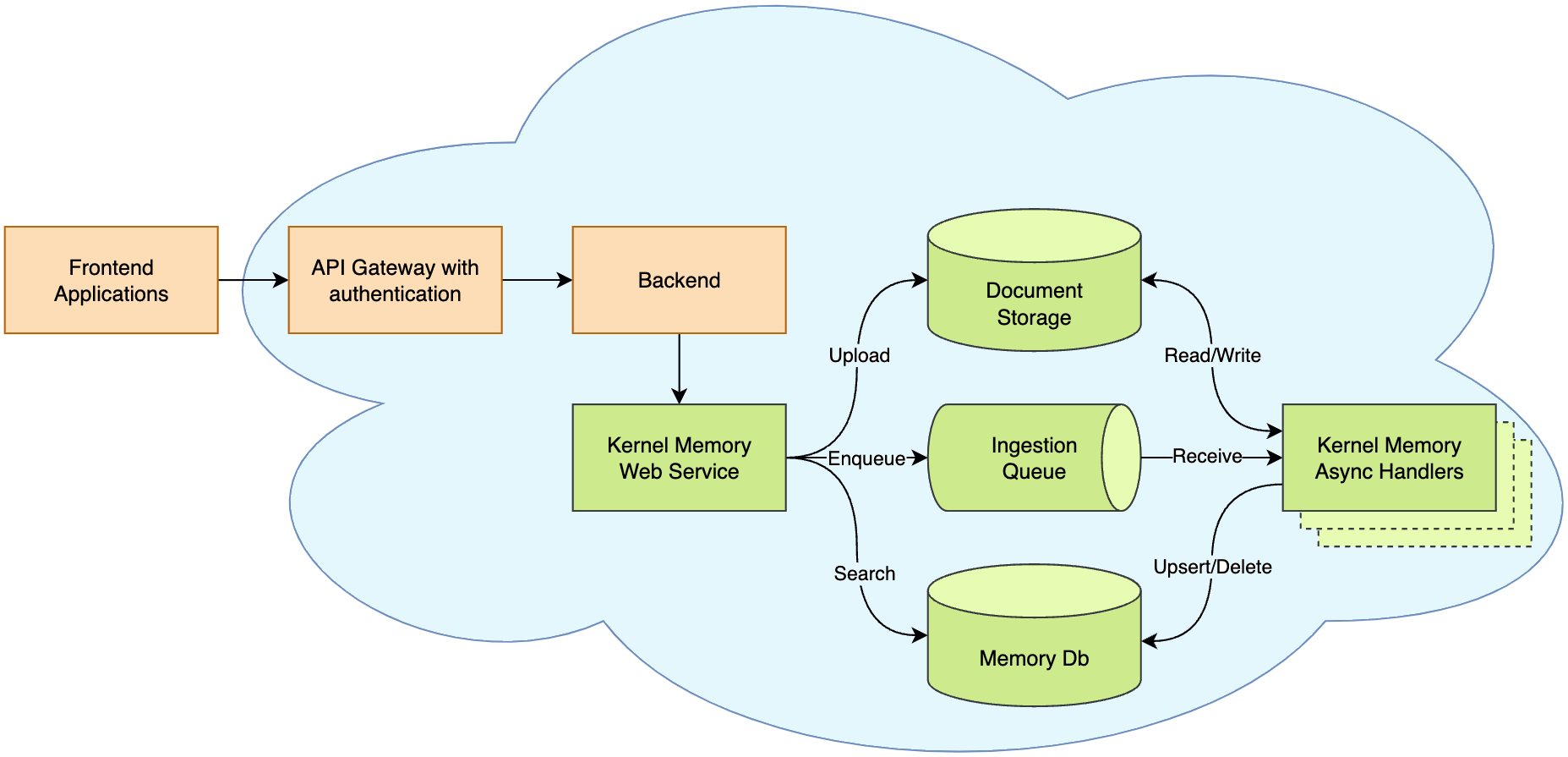
Memory as a Service - Asynchronous API
Depending on your needs, you might choose to run the code locally within your process or remotely through an asynchronous and scalable service. For small file imports that only require C# and can block the process during import, local in-process execution using the MemoryServerless class is sufficient.
However, if you need to:
- Import data and send queries via a web service.
- Use languages like TypeScript, Java, Rust, or others.
- Import large documents that take minutes to process without blocking the user interface.
- Run memory import independently, supporting failures and retries.
- Define custom pipelines using multiple languages like Python, TypeScript, etc.
Then deploying Kernel Memory as a backend service is ideal. This setup allows you to use default handlers or custom handlers in various languages and leverage the asynchronous, non-blocking memory encoding process. You can send documents and ask questions using the MemoryWebClient.
For detailed instructions on running the Kernel Memory service, refer to the official documentation.
Kernel Memory (KM) and Semantic Memory (SM)
Kernel Memory (KM) is a service built from the feedback and lessons learned from developing Semantic Kernel (SK) and Semantic Memory (SM). It offers features like file storage, text extraction, and a framework for securing user data, all in a .NET codebase. KM can be used from any language, tool, or platform, including browser extensions and ChatGPT assistants.
Semantic Memory (SM) is a library for C#, Python, and Java that supports vector search and wraps direct database calls. Developed as part of the Semantic Kernel (SK) project, it serves as the first public iteration of long-term memory. The core library is maintained in three languages, with varying support for storage engines (connectors).
Here’s a comparison table:
| Feature | Kernel Memory | Semantic Memory |
|---|---|---|
| Data formats | Web pages, PDF, Images, Word, PowerPoint, Excel, Markdown, Text, JSON, HTML | Text only |
| Search | Cosine similarity, Hybrid search with filters (AND/OR conditions) | Cosine similarity |
| Language support | Any language, command line tools, browser extensions, low-code/no-code apps, chatbots, assistants, etc. | C#, Python, Java |
| Storage engines | Azure AI Search, Elasticsearch, MongoDB Atlas, Postgres+pgvector, Qdrant, Redis, SQL Server, In memory KNN, On disk KNN | Azure AI Search, Chroma, DuckDB, Kusto, Milvus, MongoDB, Pinecone, Postgres, Qdrant, Redis, SQLite, Weaviate |
| File storage | Disk, Azure Blobs, AWS S3, MongoDB Atlas, In memory (volatile) | - |
| RAG | Yes, with sources lookup | - |
| Summarization | Yes | - |
| OCR | Yes, via Azure Document Intelligence | - |
| Security Filters | Yes | - |
| Large document ingestion | Yes, including async processing using queues (Azure Queues, RabbitMQ, File-based, or In-memory queues) | - |
| Document storage | Yes | - |
| Custom storage schema | Some DBs | - |
| Vector DBs with internal embedding | Yes | - |
| Concurrent write to multiple vector DBs | Yes | - |
| LLMs | Azure OpenAI, OpenAI, Anthropic, Ollama, LLamaSharp, LM Studio, Semantic Kernel connectors | Azure OpenAI, OpenAI, Gemini, Hugging Face, ONNX, custom ones, etc. |
| LLMs with dedicated tokenization | Yes | No |
| Cloud deployment | Yes | - |
| Web service with OpenAPI | Yes | - |
Building a Document AI Chat Experience - Docu Genie
To build a Document AI Chat experience, we’ll use an Azure Function as the backend in combination with a SharePoint Framework (SPFx) web part. The SPFx web part will serve as the user interface, allowing users to upload documents and ask questions.
The Azure Function will utilize Kernel Memory to upload documents to Blob Storage, extract and transform data, manage semantic memory, implement Retrieval-Augmented Generation (RAG), and provide answers with citations using Kernel Memory.
Architecture Overview
- SPFx Web Part: The user interface where users can upload documents and ask questions.
- Azure Function App: Manages document ingestion, indexing, and querying using Kernel Memory to upload documents to Blob Storage, extract and transform data, manage semantic memory, implement Retrieval-Augmented Generation (RAG), and provide answers with citations.
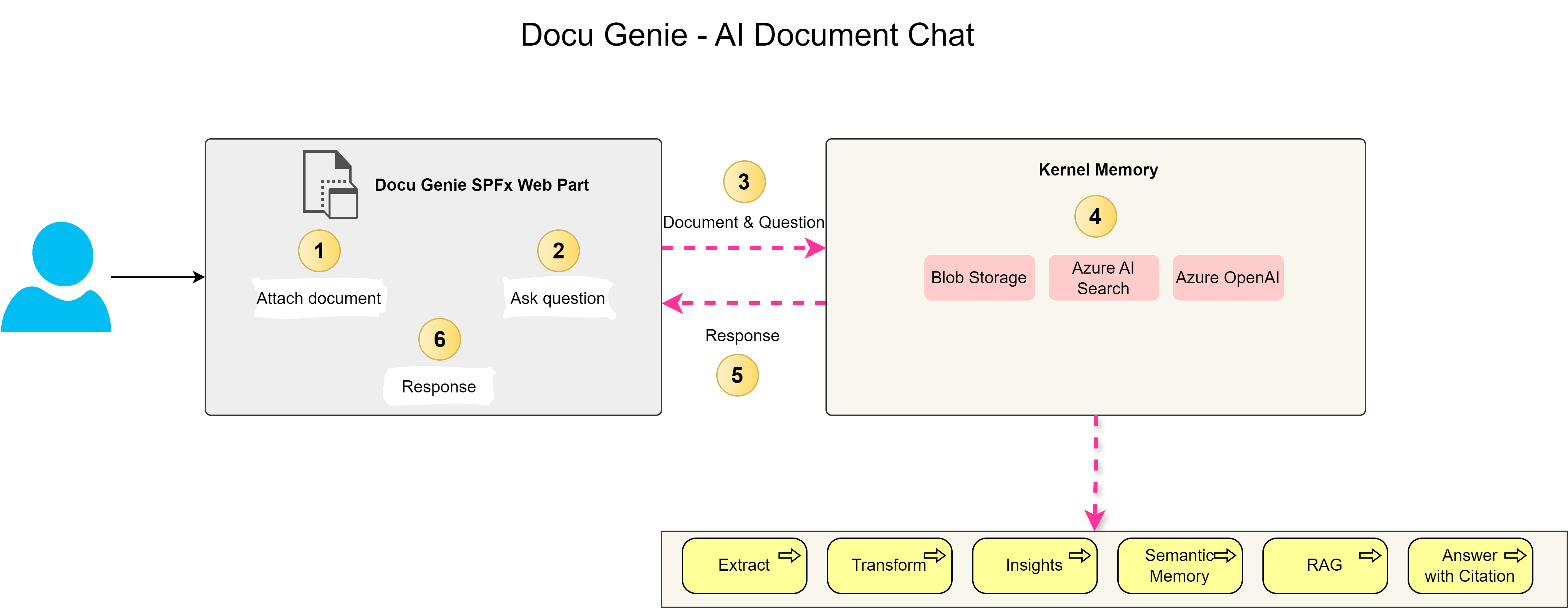
Demo
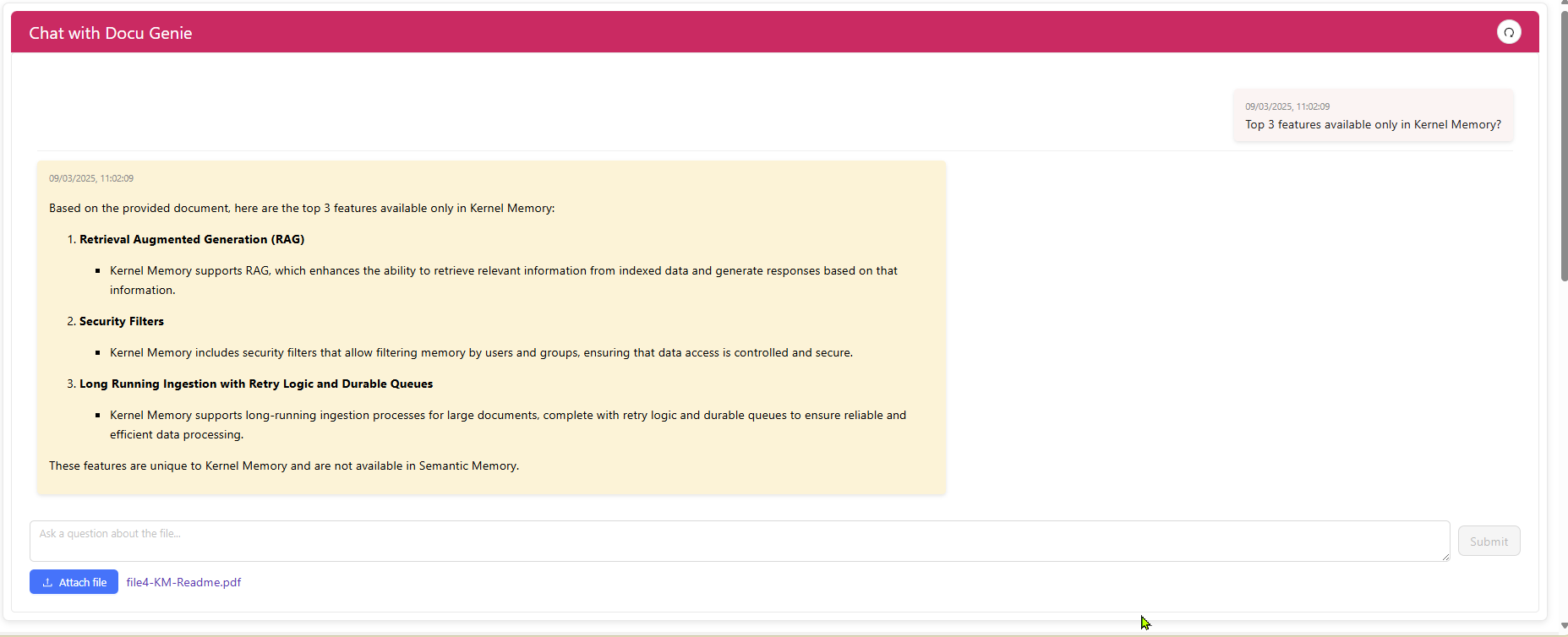
Kernel Memory Service
The Kernel Memory Service initializes Kernel Memory to manage document ingestion, indexing, and querying. It handles importing documents, extracting data, and answering user queries with accurate, citation-backed responses.
Conclusion
Microsoft Kernel Memory is a powerful tool for building AI-driven document chat experiences. By leveraging its advanced features like RAG, security filters, and long-running ingestion, developers can create robust applications that allow users to interact with their documents in natural language. Whether you’re building a simple Q&A system or a complex chat experience, Kernel Memory provides the tools you need to get started.
Source Code
Note
You can find the complete source code from react-document-ai-chat.